从PDF中提取文本真的很容易吗

在日常工作中我们会经常遇到PDF文件,大家一般认为,从PDF中提取文本应该不会太难,因为我们打开PDF就能看到文本。那么,从PDF中正确提取文本真的很难吗?到底难在哪里呢?
实际上,因为有很多的特殊情况和不正确的假设,算法和程序很难100%正确提取文本;而且因为PDF格式有极大的灵活性,要正确处理PDF也很困难。
主要原因在于,PDF格式设计伊始就不是针对的输入数据的场景(比如Word、PPT、Excel),而是作为一种输出格式,用于确保在不同的设备上始终可以看到完全相同的文档和格式(比如Word用不同版本打开可能段落、页眉页脚等会有细微差别;但PDF基本不会),可以对生成的文档进行更细粒度的控制。
PDF文件的核心内容是由描述如何在页面上绘图的指令流组成。在PDF中没有段落和行的概念,所有文字都是逐个字符放在指定位置上让人看起来是一行。这样的结果就是,我们在将文本或 Word 文档转换为 PDF 时,大部分的结构信息都丢失了——所有隐含的文本结构都被转换为放置在页面上的松散字符位置。
在长期研究知字产品PDF解析的过程中,我们从几百万个PDF 文档中提取过文本数据。在这个过程中,经常会发现我们对PDF文件结构的很多假设都被证明是不正确的。解析PDF文档的过程特别艰巨,因为我们经常要处理各种各样的,排版、样式、字体和渲染完全不同的PDF文档。
下面是一些导致PDF文件在提取文本内容非常困难的一些原因。
PDF阅读保护
您可能遇到过一些禁止复制文本内容的PDF文件。比如,这是从Adobe Acrobat Pro DC里打开一个受保护的文档,然后复制文本时显示界面:
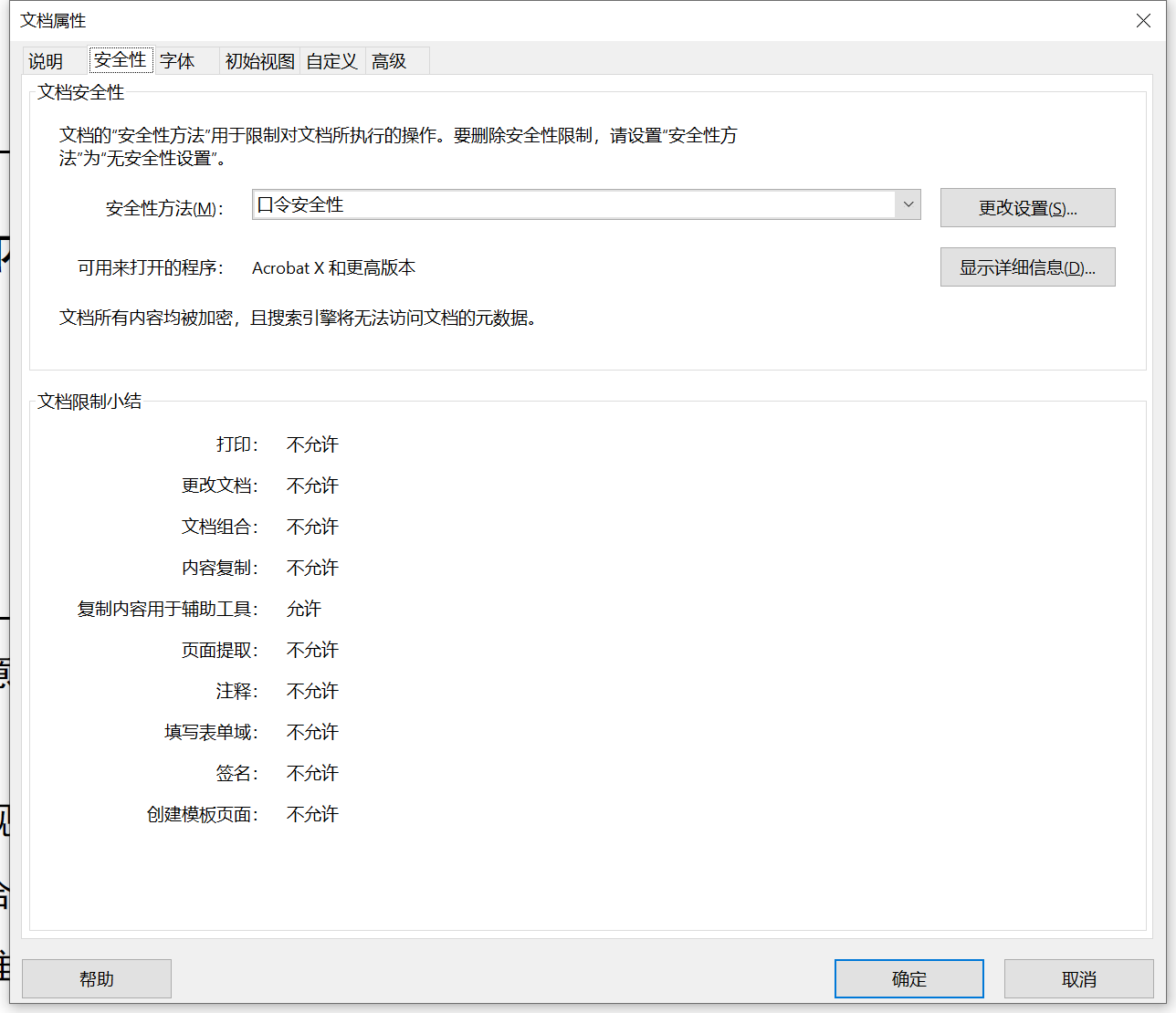
有意思的是,文本虽然能看见还可以选中,但Adobe Acrobat Pro DC依然不允许复制内容。
这是通过在PDF文档中设置了几个“访问权限”的标志,其中一个表示是否允许复制内容来实现的。但实际上,这些标志并不影响PDF文件内容的解析和读取,是否遵守这些标志完全取决于打开PDF的程序,如果你用另一个PDF阅读器打开,可能还是可以复制文本的。
所以说,这肯定不能真正意义上禁止从PDF里面提取文本,因为任何高级一些的 PDF 处理类库都允许用户随意修改或忽略这些标志。
页面范围之外的文字
PDF文件的所有内容,都是按绝对位置放置的,所以在页面范围之外放置文本的情况也不少见。(Word中也可以将文本写在文本框里,然后移动文本框到页面之外,来达到类似效果)
页面之外的文字因为没有处于页面的范围之内,所以大多数PDF预览程序都不会显示;但因为文字确实存在,如果使用PDF处理SDK读取PDF的话,就会提取到这些看不到的文字。
字号极小、不可见或位置重复的文字
字号极小
有些PDF出于某种原因,页面上可能会有些字号特别小的文字,人眼完全看不到,但如果程序提取的话会提取到。
不可见的文字
有时候一些PDF会在页面上有些看不到,但实际上存在的文本,比如用免费软件Adobe Acrobat Reader打开PDF后,按Ctrl+A选择全部文本。文本区域会以淡蓝色高亮显示:

这些文本看不到的原因主要有以下几个:
- 在某个位置绘制文本后,又用和背景颜色相同的矩形覆盖在文本上面,使文本被隐藏(图片中是这种情况)
- 文本颜色和背景颜色完全相同,使人看不到文字
位置重复的文字
某些PDF中,文字的加粗效果是通过在同一个位置,绘制两次同一个字符来实现的。(PDF中文字的加粗效果至少有四种方法)
下面是一个使用Adobe Acrobat Pro DC打开的PDF文件,进入编辑模式后,复制文本的结果。(预览模式下复制文本字符没有重复,可能是阅读器进行了去重)


文本中有冗余空格
有些时候PDF文档中,看起来连贯的文本,复制出来可能会包含额外的空格;有些是出于调整字符间距的目的:


针对这种情况,根据字符的位置计算,忽略无效的空格有时候可以解决,但也可能会导致部分空格丢失。
缺少必要的空格
还有些时候,PDF文件中可能缺少必要的空格,尤其出现在一些英文PDF中:


针对这种情况,根据字符的位置填充缺少的空格大部分情况可以解决。
PDF文件内嵌的字体
我们知道,计算机中的文字是通过编码来存储和使用的,最常见最全的编码是Unicode。
在PDF文件中虽然我们经常可以复制文字,但实际上PDF并没有直接支持Unicode;这是因为PDF是一种通用输出格式,如果使用了Unicode,就没办法在不支持 Unicode 的旧操作系统(如 Windows 98 和 Windows NT)上显示。
PDF 文件通过在内部使用另一种编码来二次映射到Unicode,其中一种比较常见的是CID(即character ID)。
另外,对于除英语之外的语言,字符不是只靠256个就能描述的,所以一般需要嵌入字体。
经常使用Word或WPS的朋友应该清楚,字体是文本的图形表示,决定了文字显示时的书写轨迹、粗细、颜色等信息。有时候电脑上缺少一种字体就需要到网站搜索下载安装才可以正常打开word文档。
而PDF格式是一种确保最终显示一致的文档格式;为了避免PDF中文档使用了某个字体,但打开PDF的设备上缺少字体而导致无法正常显示的问题,PDF格式允许将一些不常见的字体嵌入到PDF文件中。
但对于字符比较多的语言(比如中文)字体文件少则几M多则十几M,为了缩小文件体积,所以PDF一般只会嵌入字体文件的一部分:文档中用到的字符对应的字形(Glyph)。
字形,即文字的图形,描述如何绘制某个字符的指令,字体文件中每个字符都有一个或多个字形(比如常规、加粗、倾斜、加粗+倾斜)。
而字体文件中每个字形的位置,又通过GID来表示(Glyph在字体中的ID)
那怎么知道每个字形对应哪个Unicode文字呢?为了解决这个问题,PDF字体中会嵌入一个ToUnicode映射,记录了每个GID对应的Unicode值。
所以,PDF字体包含三部分:GID位置、ToUnicode Map映射、Glyph字形。通过GID可以找到对应的Unicode文字和字形
那PDF中如何使用字体中的某个文字呢?前面我们说到PDF使用的是CID来进行映射;由于PDF字体中GID可以唯一确定一个字,所以只需要创建一个CID到GID的映射就可以了,这个CID到GID的映射,叫做CMap;另一种方法是直接将GID作为CID,这样CID和GID的值就是相同的(这也是大部分文件的做法)。
让我们用一个图来更清晰的理解上面的CID、GID、Unicode、Glyph:
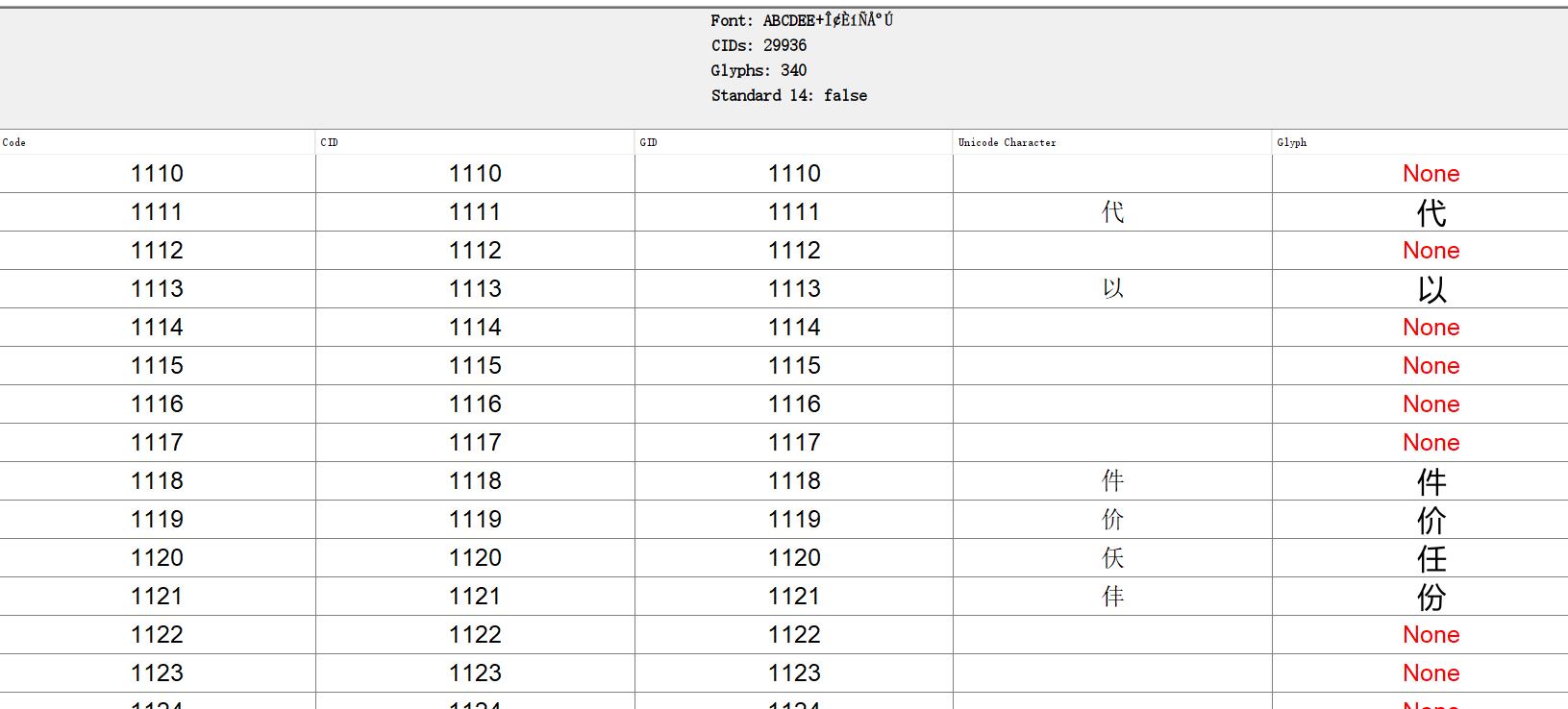
这个图的后三列:GID、Unicode、Glyph就是PDF字体的信息;最后的Glyph就是显示到屏幕上我们看到的文字形状;Unicode是这个字形对应的Unicode文本;GID是Unicode和字形的位置ID。
我们看到前面的“代”、“以”、“件”、“价”对应的Unicode都是正确的,但后面的“任”、“份”对应的Unicode都是错的;你是不是有时候也遇到过PDF中明明看到的是这句话,但复制出来后文本里面有几个是错的,或者全部乱码?
这就是原因:字形Glyph和Unicode的对应关系错了,也就是ToUnicode Map错了。
PDF只关心最终渲染呈现效果,也就是只用到了glyph字形;Unicode其实并没有用到,Unicode只是为了方便从PDF中复制文本理解字形而额外添加的一个映射信息。所以即使删除掉ToUnicode Map,PDF也能正常打开。
因为ToUnicode Map这也的一个特性,所以也有人会通过修改ToUnicode Map来达到一个间接加密的效果,使别人没办法复制和搜索文本。
PDF段落和文档结构恢复
从上面的介绍我们知道,PDF中没有段落、行的概念;所有文字都是显示到指定位置坐标来渲染的。因为文字的彼此横纵位置不一样,人们自然地能知道哪里是一段,哪里是一行。
但对于计算机程序来说,根据页面上的上千个字符,和他们对应的x,y坐标,确定哪些是一行,哪些是一段,真的是个很艰巨的任务。
比较常见的方法是使用分组或者聚类算法来根据文字大小、位置、对齐方式进行组织和判断。
但简单的位置和坐标聚类有时候也不一定能获得正确的结果,比如遇上下面这样排版复杂的PDF文件:

如果要得到准确率更好的段落和文档结构顺序,可能需要考虑结合AI和自然语言处理分析才可以了
文字是内嵌图片
一些PDF内容实际上没有文本,整页内容是一个扫描的图片。这种情况下,没办法从PDF文件本身提取文本内容了。这实际上是从图片中提取文本的问题,就需要借助OCR(光学字符识别)技术了。
单纯只有图片的其实判断还算简单,直接将这个图片经过OCR提取文本就可以了。
真正困难的是有些PDF文档,主要内容实际是一个扫描的图片,但是又掺杂了很多不可见但能提取出来的文本,这时候我应该信任提取的文字吗?还是这个图片是个背景实际上没有文字呢?
转曲文本
一些PDF文件因为字体缺失或在其他设备上不能正确显示文本,可以对PDF进行转曲操作,意思就是将文本转为曲线。PDF在使用字体绘制文本时,通常一个数字ID就表示了一个字符,转为曲线后,就没有了字体的概念,所有文字都是一笔一划“画”到PDF上,笔画少的像“大”,虽然只有三笔,但结合转曲时使用的字体对应字形是否有顿角等特点,需要15~20多个轨迹;而复杂一些的比如“我”,可能至少需要100多个曲线轨迹描述。
转为曲线之后的文本实际已经不是文本了,就像是用剪纸剪出来个图形贴到上面,本质上就是一个图形。所以要直接提取PDF中的转曲文本是没办法做到的,只能像提取图片中的文字一样使用OCR来识别。
为什么不全部通过OCR提取PDF的文字?
OCR作为PDF中提取文字的最后手段,也是针对各种错误乱码PDF的最有效手段,那为什么不把所有的PDF都通过OCR提取呢?因为OCR技术也有其自身的一些问题:
- 处理时间长:将PDF转图片经OCR提取文本所用的时间,比直接提取文本的耗时至少多一个数量级。
- 耗费资源多:目前比较成熟的OCR技术都是借助于深度学习技术,需要耗费大量CPU或GPU资源,成本相比直接提取要多很多。
- 偏僻字、易混字、多语言支持差:OCR技术的效果取决于模型和训练语料;而一些偏僻字很容易因训练不足导致识别错误。还有一些数字“1”和字母“l”在OCR中很容易混淆;另外,OCR一般是针对某种语言的,如果不知道PDF图片中的语言,很容易提取错误。
PDF提取文字最佳实践
既然从PDF中正确提取文字有这么多困难,那应该怎么简单地提取PDF中的内容呢?不要担心,还是有一些简单快速的方法的。
如果您只是想复制一些纯文本,段落和格式不重要,那您可以直接使用常见的PDF阅读器打开,然后尝试选择文本复制即可,比如免费的Adobe Acrobat Reader。
如果您想把PDF转为Word那样带格式和布局的可编辑文档,您可以在手机上搜索“知字扫描全能王”(目前只有Android端),里面的40+文档转换就允许您将PDF转为Word。如果您的PDF是文本类型,您可以先尝试直接转换为Word;如果出现了乱码或者文字丢失,可以勾选【识别PDF内图片中的文字】选项,就可以通过OCR技术从图片中提取文字了。
如果您在电脑端操作,也可以搜索“知字文档”,可以进行在线批量PDF转换哦
更多精彩文章,订阅微信公众号
